No. 001 — March 2026
Trust as a resource AI products borrow and rarely repay
Most AI products are designed to maximize user confidence, but the research on automation trust says that is the wrong goal. Trust that outruns a system's actual capabilities does not last.
Two ways to fail
Every AI product failure is one of two things.
The user trusted it too much. They accepted an output they should have questioned, acted on it, and something went wrong. Or they walked away too soon. They encountered one bad output and stopped using a tool that would have served them well.
Researchers who study human-automation interaction call these misuse and disuse. Misuse is overreliance, the user leaning on the system when they should not. Disuse is underutilization, the user rejecting a capable tool because they do not trust it enough to engage with it. Both are calibration failures, and both are design problems (Parasuraman & Riley, 1997).
The instinct in AI product development is to treat the first as success, since people are at least using the tool, and the second as an onboarding problem, since better user education would presumably fix it. The research does not support either interpretation.
Parasuraman and Riley (1997) documented this studying automation failures across aviation, process control, and nuclear operations. In one case, pilots trusted an autopilot that was failing and did not intervene until it was too late. In another, operators found alarm systems so unreliable that they taped over the buzzers rather than address why the alarms kept sounding. Two failure modes and one underlying problem. The operator's trust was not calibrated to what the system could actually do.
The autopilot scenario feels like a story about users overconfident in the system. However, it is really a story about systems designed to project competence without communicating limitations. The operators who taped over the buzzers were not reckless either. They were responding rationally to a system that had cried wolf so often that they no longer trusted its warnings. The designs created the distrust.

What trust actually is
Trust is often mistaken for confidence, for predictability, or for the simple belief that a system will work. It is none of those.
Mayer et al. (1995) drew this distinction in their model of organizational trust, which remains the most cited framework in the literature. A system can be predictably bad. An organization can be predictably self-serving. Predictability without good intent is not trust. It is pattern recognition; you learn what to expect and adjust.
Trust, in their formulation, is "the willingness of a party to be vulnerable to the actions of another party, based on the expectation that the other will perform a particular action important to the trustor, irrespective of the ability to monitor or control that other party". Two conditions have to be present for this to happen. Uncertainty and stakes. The trustor cannot fully verify what the trustee is doing, and they have something real to lose if the trustee fails them.
Both conditions hold in almost every AI product interaction. If the user cannot audit the model's output, they are staking something real on it, a decision, a document, a client deliverable. Trust is the relational condition that makes the product usable.
Lee and See (2004) make a related point. Trust guides reliance precisely when complexity and unanticipated situations make a complete understanding of the automation impractical. The more opaque the system, the more work trust has to do. Which means the more opaque the system, the more carefully trust has to be designed.
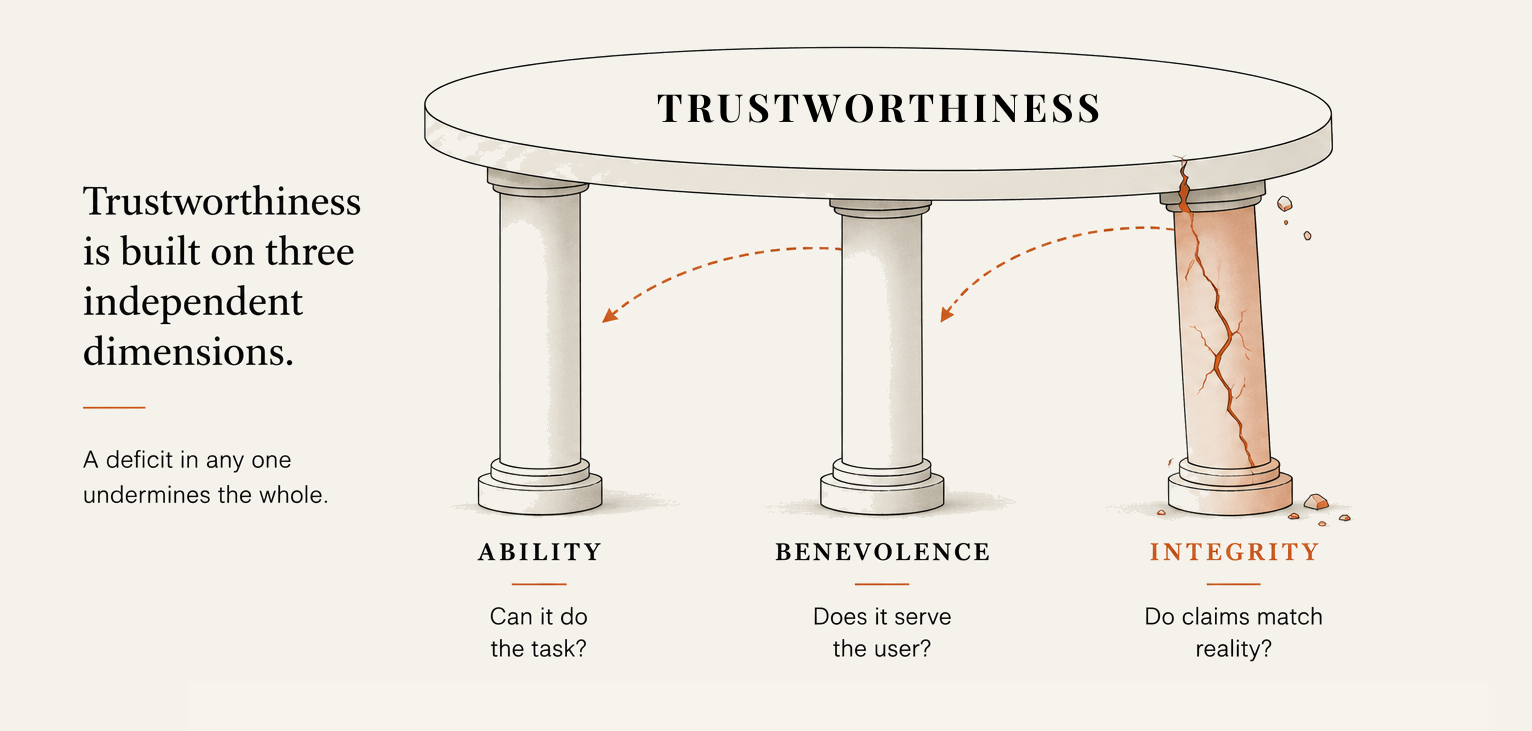
What trustworthiness is made of
Mayer et al. (1995) identified three components of trustworthiness. Each can fail independently.
Ability is domain-specific competence. A system that writes excellent code is not thereby trusted to summarize clinical trials. Ability is task-bound, and trust built in one domain does not transfer automatically to another. Products that present a single AI agent as universally capable are borrowing trust from one domain and spending it in another (Mayer et al., 1995).
Benevolence is orientation toward the user's interest, distinct from the product's interest. This is the component most AI product teams do not discuss. Engagement optimization, completion metrics, and upsell surfaces are benevolence questions. When a system nudges the user toward an action that benefits the product more than the user, that is a benevolence failure. It does not read as one because the interface does not label it as such, but the user eventually notices that their interest and the system's interest are not the same thing. Trust erodes accordingly, and the cause is rarely diagnosed correctly.
Integrity is the match between what is claimed and what is delivered. This is where most AI trust damage originates. When a product claims high accuracy in its marketing and produces unreliable outputs in practice, that is an integrity failure. When a system presents uncertain, probabilistic outputs with the same confident tone it uses for well-established facts, that is also an integrity failure. The words themselves may not be wrong in any single instance. The gap is between the implied confidence and the actual confidence, and the user is left to discover the difference on their own.
Each component contributes to trustworthiness as a whole, but a deficit in any one of them is enough to undermine the rest. Baughan et al. (2023) found that outputs that were clearly wrong after the system had correctly heard and understood the user (response failures) damaged all three dimensions simultaneously. An integrity failure does not stay contained. It revises the user's read of ability and benevolence at the same time.
Why trust is borrowed
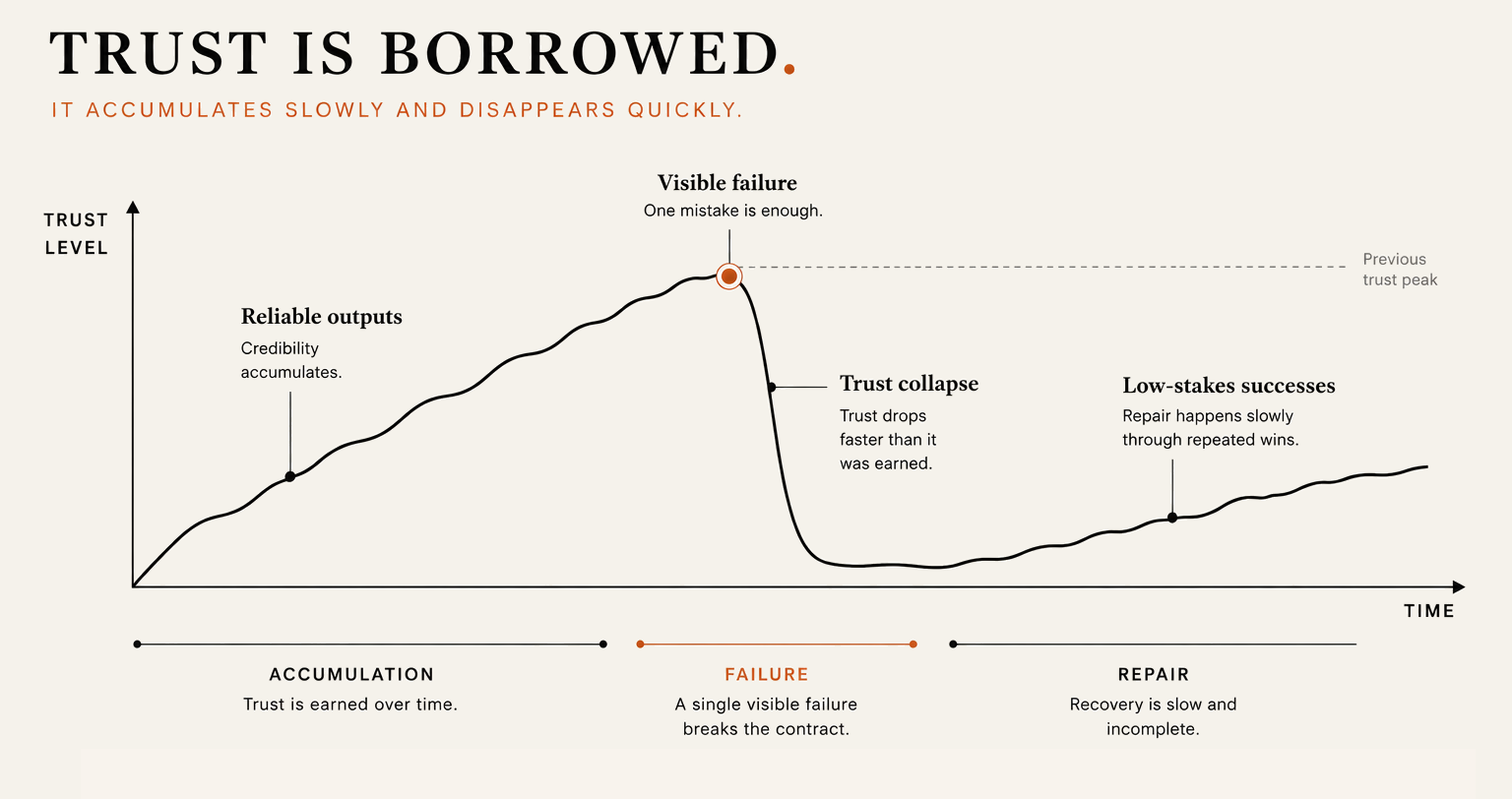
AI products earn trust through streaks. Reliable outputs accumulate credibility, and users learn to rely without verifying. That sounds irrational, but it is an efficient adaptation to a tool that appears to work. The real problem is what happens next.
Dietvorst et al. (2015) ran five studies on this and found something designers need to reckon with directly. People lose confidence in algorithmic forecasters faster than in human forecasters after seeing them make the same mistake, even when the algorithm's overall performance was better. The people who watched the algorithm outperform the human in the first stage of the study were, in every experiment, among the least likely to choose the algorithm afterward. Seeing the algorithm win, and then seeing it err, was worse than never seeing it perform at all.
A GPS that routes you into a traffic jam is less trusted afterward than a friend who gave you the same bad advice even though both were wrong. One is forgiven more readily because the psychological contract is different.
The size of the error does not matter much either. Smaller algorithm errors did more damage to user confidence than larger human errors in the same studies (Dietvorst et al., 2015). A product cannot earn its way out of the trust problem by running up a long streak of correct outputs, because the credit does not accumulate at the same rate that the damage from visible failure depletes it.
There is a setup problem too. People approach new automated systems with unrealistic expectations. Dietvorst et al. (2015) found that even participants with direct experience using a tool in the study expressed dramatically optimistic beliefs about what it should be able to do. What gets borrowed is trust against a standard no system can maintain. When the system fails, it falls not from its actual capability level but from the level the user had been led to expect. That is partly a product problem and partly a marketing problem. Onboarding copy that overclaims shortens the window before the first trust collapse.
The designer's accountability
None of this is a user problem.
Parasuraman and Riley (1997) made the accountability argument. Automation does not replace the operator. It substitutes the designer for the operator. Every decision about what the AI surfaces, how it signals confidence, when it declines to answer, and what it presents as settled is the designer's judgment, running at scale, in every interaction, without the designer present to course-correct.
When a human expert gets something wrong, one person is affected. When the designer's embedded judgment is wrong, every user who encounters that situation is affected simultaneously. That is a different failure mode than individual operator error. The scale changes what accountability requires.
The positivity bias compounds the problem. Hoff and Bashir (2015) found across automation trust studies that people assume new systems will perform at a high level, often higher than the system warrants. That initial trust is given, not earned. It is the capital the product borrows before it has done anything to deserve it.
Lee and See (2004) are direct about what this means for design. The goal is appropriate trust, not greater trust. They call this calibration, the correspondence between a person's trust in the system and the system's actual capabilities. A product that makes users feel more confident than the system warrants is failing the calibration requirement and spending capital it cannot repay.
Applying the framework: an AI accessibility audit tool
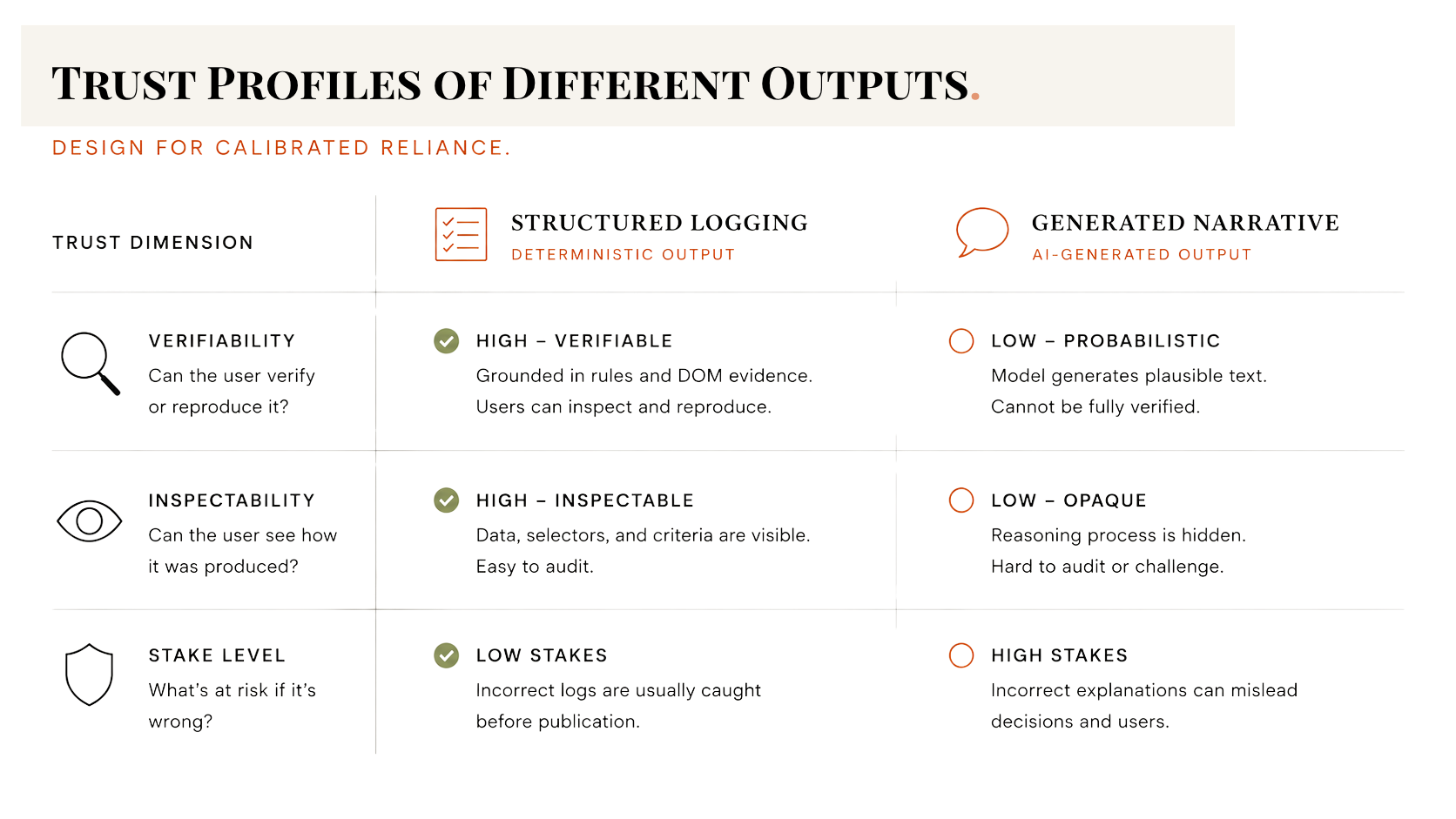
Consider a tool we have been building. It does two things. It logs accessibility issues in a structured way, tied to WCAG (Web Content Accessibility Guidelines) criteria, and it generates conformance narratives for reports with AI. Two outputs, same interface, very different trust profiles.
The structured logging is deterministic enough that users can verify it. A criterion was flagged or it was not. The logic is inspectable. If the tool flags a missing alt attribute, the user can check the element and confirm. Ability, benevolence, and integrity are all testable in that interaction.
The AI-generated narrative is different. It synthesizes findings into prose that sounds authoritative, because that is what the model was trained to produce. However, the confidence of the prose does not track the confidence of the underlying judgment. A generated paragraph explaining why a component fails WCAG 1.4.3 may be accurate, or it may be plausible-sounding and wrong in a way that only an expert reviewing it carefully would catch. In a client-facing report, that matters.
If both outputs are presented with the same visual weight and the same confident tone, the designer has made an integrity decision by omission. There is no signal about which part to trust more. The user who verifies neither is not being careless. They are responding to a design that gave them no reason to distinguish between the two.
Applying the framework means making the distinction legible before the user discovers it through a failure. The structured logging and the generated narrative are different kinds of outputs with different confidence profiles, and the interface should reflect that. A disclaimer buried in a help modal does not do it. The difference has to be visible in the interaction itself, at the point where the user decides how much to rely on what they are reading.
The sequencing of trust-building matters too. Users should encounter the low-stakes, verifiable outputs first, enough times that their confidence in those outputs is calibrated correctly before they engage with the higher-stakes generative ones. A user who has logged fifty issues and confirmed the tool's structured outputs are reliable has a calibrated basis for deciding how carefully to review the AI-generated narrative.
If the generated narrative is wrong, the response has to match the failure type. Baughan et al. (2023) found that errors users can attribute to ambiguity in their own input are forgiven. Errors the system made without ambiguity, where the output was clearly wrong and the user's input was clearly right, hit all three trust dimensions hard. A confident wrong answer in a client report is that second kind of failure. A generic "AI can make mistakes" disclaimer does not address the damage and it may actually worsen it by appearing to minimize what happened.
Trust repair after failure runs through low-stakes task success, not through explanation or apology (Baughan et al., 2023). A tool that routes every interaction through high-stakes outputs leaves no repair path. Structured logging, issue tagging, and WCAG citation lookup are lower-stakes interactions in the same tool that give users a way to rebuild confidence before they return to the generative output. One bad narrative should not end the relationship. The design has to make sure it does not.
None of these are edge cases. They are the normal operating conditions of a tool that combines deterministic and generative outputs in the same interface. The trust problem has to be designed for before the first user encounters it.
The argument
Trust in AI products is borrowed against an implicit contract. The system will perform a particular action that matters to the user, in a situation where the user cannot fully verify the output. That contract is created by design, by what the product claims, how it presents confidence, and what it asks users to stake on its outputs.
When the system fails visibly, the contract breaks. The damage is faster than most designers expect, and the recovery is slower. It does not run through explanation or apology. It runs through low stakes, adjacent domains, and enough successful interactions that the user has a reason to try the harder thing again.
Trust is not a user problem to manage. It is a design resource to steward. The research has been saying this since 1997. AI products have not been listening.
References
Baughan, A., Mercurio, A., Liu, A., Wang, X., Chen, J., & Ma, X. (2023). A mixed-methods approach to understanding user trust after voice assistant failures. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (Article 373). ACM. https://doi.org/10.1145/3544548.3581152
Dietvorst, B. J., Simmons, J. P., & Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General, 144(1), 114–126. https://doi.org/10.1037/xge0000033
Hoff, K. A., & Bashir, M. (2015). Trust in automation: Integrating empirical evidence on factors that influence trust. Human Factors, 57(3), 407–434. https://doi.org/10.1177/0018720814547570
Lee, J. D., & See, K. A. (2004). Trust in automation: Designing for appropriate reliance. Human Factors, 46(1), 50–80. https://pubmed.ncbi.nlm.nih.gov/15151155/
Mayer, R. C., Davis, J. H., & Schoorman, F. D. (1995). An integrative model of organizational trust. Academy of Management Review, 20(3), 709–734. https://doi.org/10.2307/258792
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253. https://doi.org/10.1518/001872097778543886