No. 003 — July 2026
The Design System Is Not the Foundation. It Is the Problem.
Most design systems treat accessibility as something you can measure on the visual surface, a contrast ratio here, a labeled component there. The failures that keep the web inaccessible live in the interaction layer those systems never specify.
The Same Six Errors, Every Year
The WebAIM Million is an annual audit of the top one million home pages on the web. In 2025, it found that 94.8% of those pages had detectable accessibility failures. That number has not moved meaningfully in seven years. The six most common errors (low contrast text, missing image alt text, empty links, missing form labels, missing document language, and empty buttons) are the same six that topped the list the year before, and the year before that.
This is not simply a developer awareness problem. Accessibility has never had more documentation, more tooling, more conference talks, or more organizational commitment than it does now. Mack et al. (2021) surveyed every accessibility paper published at CHI (the ACM Conference on Human Factors in Computing Systems) and ASSETS (the ACM Conference on Computers and Accessibility) from 1994 to 2019 and found the field grew faster than CHI itself, reaching nearly 8% of all CHI papers by 2019. The papers kept coming, but the web did not get more accessible.
Paiva et al. (2021) reviewed 94 studies on accessibility in software engineering practice and found that the dominant research focus across three decades was testing and design, with testing concentrated at the quality assurance phase. Accessibility audits happen at the end of the pipeline, while solutions are applied in code. The best fix for many complex accessibility issues, the authors note, would be to revisit the overall approach rather than patch the output. Almost no teams do that, because the process does not ask them to.
When AI entered the picture, the pattern held. Aljedaani et al. (2024) evaluated 88 websites generated by ChatGPT and found that 84% had accessibility problems. The violations were the familiar ones, the same issues found in websites built by human developers, replicated at speed. That replication pattern is the clue. The errors are downstream symptoms of something built into the infrastructure above them.
What Design Systems Actually Encode
A design system is a set of decisions encoded at a level of abstraction that individual practitioners don't have to revisit. That is what makes them useful, and it is what makes them consequential. Every one of those encoded decisions carries a view of what good design means, who the user is, and what accessibility requires.
Most production design systems, the ones that ship in products used by millions of people, define accessibility at the token layer. Token-first systems specify contrast ratios, type scale relationships, spacing units, component state labels, and ARIA role annotations, all of them measurable properties of visual artifacts. You can run a linter against them. You can fail a pull request on them. That legibility is genuinely useful, and it would be wrong to dismiss it.
However, the problem is not what these systems contain. It is what they treat as the floor.
Fogli et al. (2014) spent years building a design pattern language specifically for web accessibility. The paper is one of the most direct attempts in the literature to build accessibility-first design tooling rather than accessibility-as-overlay. Even so, the authors acknowledge that existing design patterns for accessibility, including their own starting point, were "mainly concerned with static aspects of Web sites, such as colors, fonts, page layout, links, or table structure." The visual and static layer has been the default even for researchers trying to escape it.
Paiva et al. (2021) reviewed the full body of software engineering research on accessibility from 2011 to 2019 and found no reference architecture for accessibility in the software design phase. None. There is substantial literature on testing methods, on guidelines, on assistive technology evaluation. There is almost no literature on what an accessibility-first design specification would structurally require.
Stephanidis et al. (2001) provide the most precise diagnosis of why. In their framework for Unified User Interfaces, they describe accessibility as operating across four levels, running from physical properties and constructional elements up through syntactic dialogue sequencing to semantic meaning. Current design system tokens operate almost entirely at the physical level. They occasionally reach the constructional level through component variants and state classes. The syntactic level, which governs how a person sequences through a task, and the semantic level, which governs what the interface is communicating and doing, are not addressed.
Nobody overlooked this. Visual consistency is easier to specify, easier to measure, and easier to sell than interaction contracts, and the incentive structure around design systems has consistently rewarded what can be tokenized.
The question of whether any production system leads with interaction rather than visuals deserves a direct answer. Looking across Material Design, Adobe Spectrum, Radix, and the systems built on top of them, the answer is no. Not in production, and not in any form that an AI code generator or a product team could consume as a specification for interaction behavior. The closest attempts are academic. The most developed one is Fogli's, and it was a prototype.
The Idea Is Not New. The Architecture Is.
The argument that accessibility belongs at the behavior and interaction layer is not recent. In 2001, Stephanidis et al. described what a unified user interface would require at an architectural level, and identified the unsolved problem as the representation and deployment of design logic in computable forms, to enable what they called run-time design assembly.
A decade later, Wobbrock et al. (2011) made the philosophical case for reorienting accessible design entirely. The right question when designing accessible technology, they argued, is not "what disability does a person have?" but "what can a person do?" That reorientation, from disability-as-category to ability-as-context, is the same move Stephanidis made architecturally. The system should be built to fit whoever uses it, not to accommodate deviations from an assumed average. Wobbrock named this the principle of Accountability. The burden of conforming belongs to the system, not the user.
Three years after that, Fogli et al. (2014) built the thing. Their design pattern language for rich internet application accessibility organized its patterns into Presentation, Navigation, and Interaction columns. At the top of the hierarchy sat a high-level pattern called Interaction at user's pace, an interaction contract rather than a color token or a font scale. The patterns were evaluated with real designers on real projects and produced working accessible applications. The system worked. It ran out at the complexity boundary. The two designers who evaluated it flagged the absence of patterns for sliders, scroll bars, and drag-and-drop behaviors. Those are exactly the interaction types that automated testing cannot fully evaluate and that current AI code generators most reliably fail.
Mack et al. (2021) document why none of this propagated into mainstream practice. Their literature survey shows that accessibility research concentrated on blind and low-vision users, on specialized assistive technology, and on technology innovation rather than systemic design change. The field itself defaulted to the visual and the legible. The authors note that this skew was likely driven by "the apparent concreteness of visual accessibility problems to HCI researchers." The research community reproduced, in its own publication patterns, the same bias toward the measurable surface that design systems reproduce in their token structures.
Twenty-five years after Stephanidis specified the architecture, the design system the literature has been converging on does not exist in production.
What Interaction-First Actually Means
An interaction-first design system is an engineering specification, and the literature has described what it requires.
Stephanidis et al. (2001) provide the most complete version. A unified user interface needs four components.
- Alternative implemented dialogue artifacts covering the range of ways a person might interact with a given pattern.
- User and context parameters that describe who is interacting and under what conditions.
- Decision logic that selects among the alternatives given those parameters.
- Interface control that applies the selected alternative.
Current design systems provide the first component only, and only for visual properties. The other three are absent.
Wobbrock et al. (2011) add the philosophical architecture. The system should start from ability, not disability. And ability moves with context. A person's ability to read small text varies by ambient light and screen angle. A person's ability to use fine motor controls varies by fatigue, injury, and distraction. These are ordinary conditions, not edge cases. Wobbrock calls them situational impairments, and he documents that designs serving people with disabilities routinely improve the experience for people without them. An interaction-first design system treats this context-dependence as a specification requirement, instead of a bonus feature.
Fogli et al. (2014) translate this into a usable architecture. Their pattern language introduces the concept of forces, the competing design pressures that act on any interaction decision and the reasoning about how accessibility criteria bear on them. A force is a structured argument about tradeoffs. A color contrast ratio is a pass/fail threshold. A force says, here is the interaction context, here is why it creates difficulty for users with certain abilities, here are the constraints in tension, and here is how this pattern navigates them. That distinction matters for AI. A model reasoning from forces can navigate tradeoffs. A model applying tokens can only apply them or fail to.
Mack et al. (2022) put this in operational terms. Their research on accessible human-centered methods found that access needs cannot be prepared once and applied universally. They require anticipation of the range of needs and continuous adjustment as specific contexts emerge. The word they use is anticipate, not accommodate. Accommodation responds to a known specific need after a default has been established. Anticipation encodes the expectation of diverse needs into the default itself. An interaction-first design system is, structurally, a system that anticipates. The visual-first system accommodates, if it accommodates at all.
The practical consequence of this distinction is what Mack et al. (2022) call the access differential, which is the extra labor imposed on people who do not match the assumed default user. Default tools, whether Figma, a component library, or an AI code generator, encode assumptions about who uses them. When those assumptions are wrong, the person who doesn't match pays the cost in time, workarounds, and friction. An interaction-first design system moves that cost out of individual negotiation and into structural infrastructure.
What AI Inherits, and What That Ceiling Looks Like
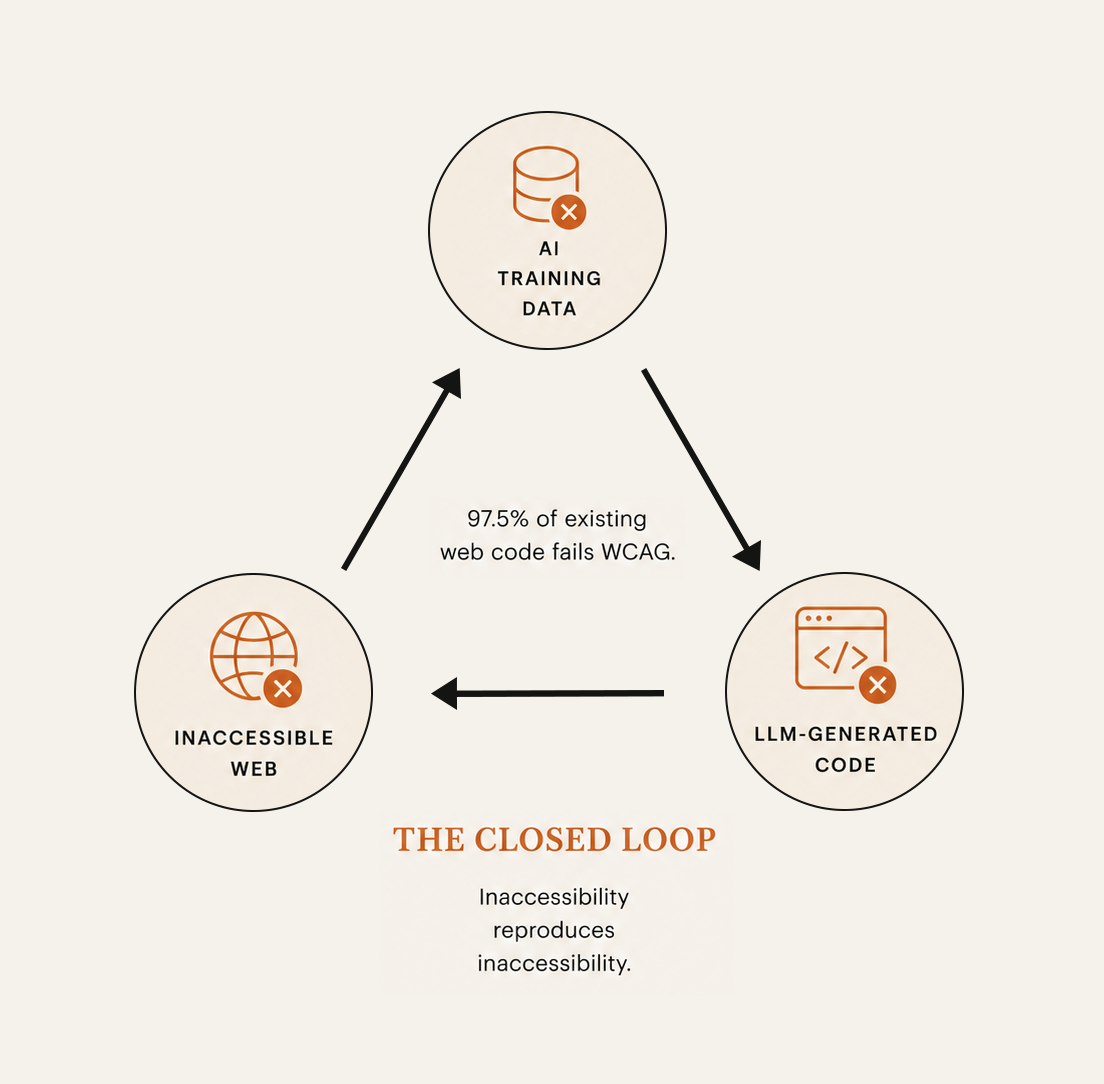
AI code generation tools fail at accessibility for the same reason design systems do. They learned from a web that was built on the wrong foundation.
Guriță and Vatavu (2025) make the mechanism explicit. They evaluated LLM-generated interfaces against WCAG 2.1 criteria using both automated testing and expert evaluation, comparing outputs from accessibility-agnostic and accessibility-oriented prompts across ChatGPT and Claude. Their background review notes that 97.5% of existing web code fails to meet basic accessibility standards. When a model trains on that corpus, it learns inaccessibility as the default pattern. The cycle is self-reinforcing. Inaccessible web produces inaccessible training data, which produces models that generate inaccessible code, which produces more inaccessible web. Guriță and Vatavu call this a state of stagnation. Without a systematic shift in how the community approaches accessible design, improvements tend not to accumulate.
The Aljedaani et al. (2024) baseline from the introduction fits this mechanism. The violations in those 88 ChatGPT-generated sites concentrated in the Perceivable principle, meaning visual and perceptual properties, like contrast, text resizing, non-text content. Operable violations were less frequent but more serious in consequence, particularly for users with motor impairments and people using assistive technologies.
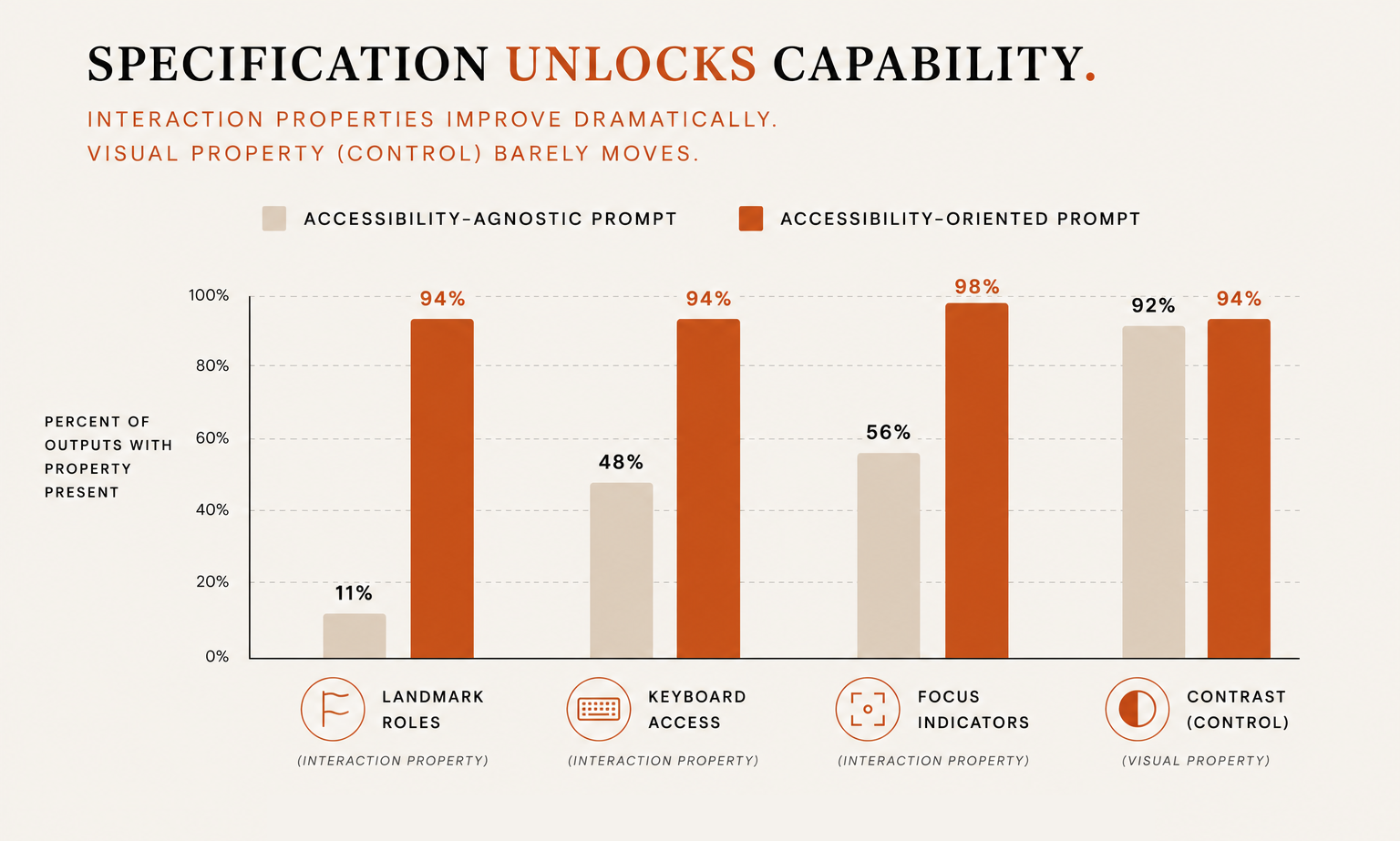
The specification dependency finding is where the argument turns. When Guriță and Vatavu (2025) gave models an accessibility-oriented prompt that spelled out interaction-level requirements explicitly, including proper headings, ARIA landmarks, labeled form controls, and minimum touch targets, the results changed substantially. Landmark roles went from 11% implementation to 94%. Keyboard access went from 48% to 94%. Focus indicators from 56% to 98%. On these numbers, the capability was there all along. What was missing was the specification. A model given interaction requirements implements them. A model given only visual tokens and functional descriptions leaves them out.
That finding sets up the obvious question: what happens if you align the model directly for accessibility rather than relying on prompting? Yoon et al. (2025) built A11YN to answer it. They used Group-Relative Policy Optimization to fine-tune a code-generating LLM with a reward function built on WCAG violation detection, penalizing violations by severity. The result was a 60% reduction in inaccessibility rate compared to the base model, with no meaningful loss in visual quality or semantic fidelity. Landmark violations dropped from 894 to 143. Color contrast violations from 702 to 418. The model learned to produce structurally accessible HTML as a default behavior rather than as an explicit request.
There is a ceiling though.
GPT-4.1 and Claude Sonnet 4 both appear in the A11YN evaluation as baselines. Their inaccessibility rates were 0.27 and 0.29 respectively. A11YN reached 0.15. These are large, capable models trained on enormous corpora. Scale did not help them past the 0.27 floor. Alignment helped more than scale, but even the aligned model retained critical violations, reduced from 40 to 24. Serious violations dropped from 978 to 481, cut roughly in half.
Guriță and Vatavu (2025) name the reason the ceiling exists. Current LLMs, they write, "often produce technically correct but practically inadequate solutions, particularly evident in their handling of semantic HTML structure and information architecture." The accessibility-oriented prompt improved WCAG compliance across most criteria but did not close the gap on interactive accessibility requirements. LLMs understand code structure. They do not understand the relationship between that structure and actual user experience.
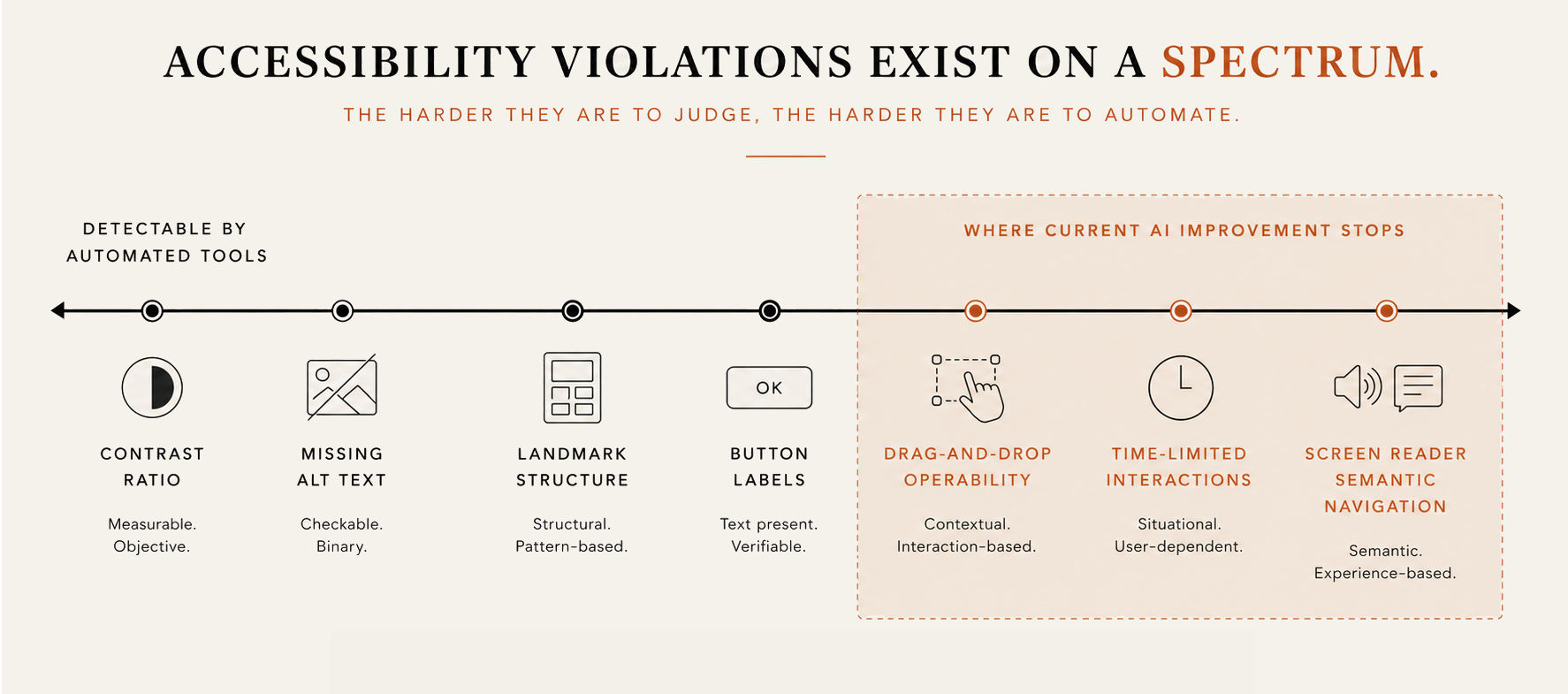
The reward function in A11YN is built on Axe-core, a WCAG auditing tool. Axe-core is excellent at what automated testing can detect. It will flag a missing landmark, a weak contrast ratio, absent alt text, an empty button. It cannot detect whether a drag-and-drop interaction is operable for a person using switch access. It cannot evaluate whether a time-limited interaction gives adequate response time for a person with a motor impairment. It cannot assess whether a complex widget is navigable with a screen reader in a way that makes semantic sense. The reward function is bounded by what it can measure, and what it can measure skews toward the visual and structural layer. The interactive layer, the one Fogli et al. ran out at in 2014, remains the hardest to specify, hardest to test, and most consequential for the people most excluded by current design.
Aljedaani et al. (2024) put a number on the practical ceiling. ChatGPT achieved a 70% success rate in fixing accessibility violations it had introduced itself. For open-source websites written by human developers, the rate was 73.4%. Both numbers stop where automated detection stops, which is why manual checks and human expertise remain necessary. The model can repair what automated testing catches. It cannot reason about what automated testing misses.
This is not an argument against using AI for accessibility work. The 60% improvement from alignment is not trivial. The improvement from explicit specification is even larger. The argument is that AI is an amplifier of its input. A behavior-first design system would give it substantially better input than a token-first one. How much better is an open empirical question, because the system does not yet exist to test against.
What Building It Would Require
The literature has specified this system in enough detail to build from.
The Stephanidis four-level stack sets the build order. Current systems are built from the bottom up, beginning with physical tokens. A behavior-first system starts at the top, with semantic interaction contracts, and descends to visual specification only after the interaction logic is established. Wobbrock's Accountability principle sets the width: those contracts have to cover the range of human ability before any visual decision is made.
Fogli et al. (2014) show the approach can work in practice. Designers using their pattern language built accessible applications without reconstructing accessibility logic from WCAG at every decision point. Where it ran out, at sliders, drag-and-drop, and scroll bars, is where the next attempt has to hold, because those behaviors need the richest interaction contracts and the most context-sensitive decision logic.
Mack et al. (2022) set the reliability bar. Even expert accessibility practitioners could not navigate access needs without structural support, so a system that depends on practitioners reasoning from token documentation at every decision point will fail the same way. The contracts have to live in the defaults.
HCI Design Lab is building that system. A follow-up article will test what happens when an AI code generator receives a behavior-first design system as its specification input rather than token-first defaults. The question the current evidence points to but cannot yet answer is whether a model given proper interaction contracts can close the gap on the interactive accessibility failures that neither prompting, alignment, nor scale has resolved.
The Closing
The accessibility crisis is not a deficit of intention. Developers care. Designers care. The research community has been publishing for thirty years. The tools have multiplied. The guidelines are everywhere.
What has not been built is the infrastructure layer where the problem actually lives. Design systems are that layer. They are what practitioners use to make decisions and what AI learns from when it generates interfaces. As long as they define accessibility as a visual property to be measured after the design is complete, the same six errors will appear at the top of the WebAIM audit every year. More tools applied to a flawed foundation produce more compliant failures, not fewer.
The research has known for twenty-five years what a better foundation would require. The question now is whether it gets built, and whether it works. That is what our ongoing research on this topic will report.
References
Aljedaani, W., Habib, A., Aljohani, A., Eler, M. M., & Feng, Y. (2024). Does ChatGPT generate accessible code? Investigating accessibility challenges in LLM-generated source code. In Proceedings of the 21st International Web for All Conference (W4A '24). ACM. https://doi.org/10.1145/3677846.3677854
Fogli, D., Parasiliti Provenza, L., & Bernareggi, C. (2014). A universal design resource for rich internet applications based on design patterns. Universal Access in the Information Society, 13(2), 205–226. https://doi.org/10.1007/s10209-013-0291-6
Guriță, A.-E., & Vatavu, R.-D. (2025). When LLM-generated code perpetuates user interface accessibility barriers, how can we break the cycle? In Proceedings of the 22nd International Web for All Conference (W4A '25). ACM. https://doi.org/10.1145/3744257.3744266
Mack, K., McDonnell, E., Jain, D., Wang, L. L., Froehlich, J. E., & Findlater, L. (2021). What do we mean by "accessibility research"? A literature survey of accessibility papers in CHI and ASSETS from 1994 to 2019. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (Article 371). ACM. https://doi.org/10.1145/3411764.3445412
Mack, K., McDonnell, E., Potluri, V., Xu, M., Zabala, J., Bigham, J., Mankoff, J., & Bennett, C. (2022). Anticipate and adjust: Cultivating access in human-centered methods. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. ACM. https://doi.org/10.1145/3491102.3501882
Paiva, D. M. B., Freire, A. P., & de Mattos Fortes, R. P. (2021). Accessibility and software engineering processes: A systematic literature review. Journal of Systems and Software, 171, 110819. https://doi.org/10.1016/j.jss.2020.110819
Stephanidis, C., Savidis, A., & Akoumianakis, D. (2001). Engineering universal access: Unified user interfaces [Tutorial]. Universal Access in Human-Computer Interaction Conference (UAHCI 2001).
WebAIM. (2025). The WebAIM Million: The 2025 report on the accessibility of the top 1,000,000 home pages. WebAIM. https://webaim.org/projects/million/
Wobbrock, J. O., Kane, S. K., Gajos, K. Z., Harada, S., & Froehlich, J. (2011). Ability-based design: Concept, principles and examples. ACM Transactions on Accessible Computing, 3(3), Article 9. https://doi.org/10.1145/1952383.1952384
Yoon, J., Cho, J., Kim, J., Chung, J., Jeon, J., & Yu, Y. (2025). A11YN: Aligning LLMs for accessible web UI code generation (arXiv:2510.13914). arXiv. https://arxiv.org/abs/2510.13914