No. 004 — July 2026
Human in the Loop, Expert Out of Practice
Every serious AI deployment ends with the same safety clause: a human reviews the output. That clause assumes the reviewer's expertise is a fixed quantity. Forty years of automation research, and now the first clinical evidence, say it is not.
Three months to measurable decline
At the end of 2021, four endoscopy centres in Poland introduced AI-assisted polyp detection as part of a large clinical trial. After the rollout, colonoscopies were randomly assigned to run with or without AI assistance. That created an accidental experiment. You could watch what happened to the doctors' unassisted performance after they had been working alongside the AI.
It dropped. Budzyń et al. (2025) compared 1,443 non-AI-assisted colonoscopies from the three months before and the three months after the AI was introduced, a window running from September 2021 to March 2022. The adenoma detection rate fell from 28.4% to 22.4%, an absolute decline of 6 percentage points (95% CI -10.5 to -1.6). In the multivariable analysis, exposure to AI was independently associated with lower detection (odds ratio 0.69). Adenoma detection rate is one of the strongest predictors of whether a patient later develops colorectal cancer.
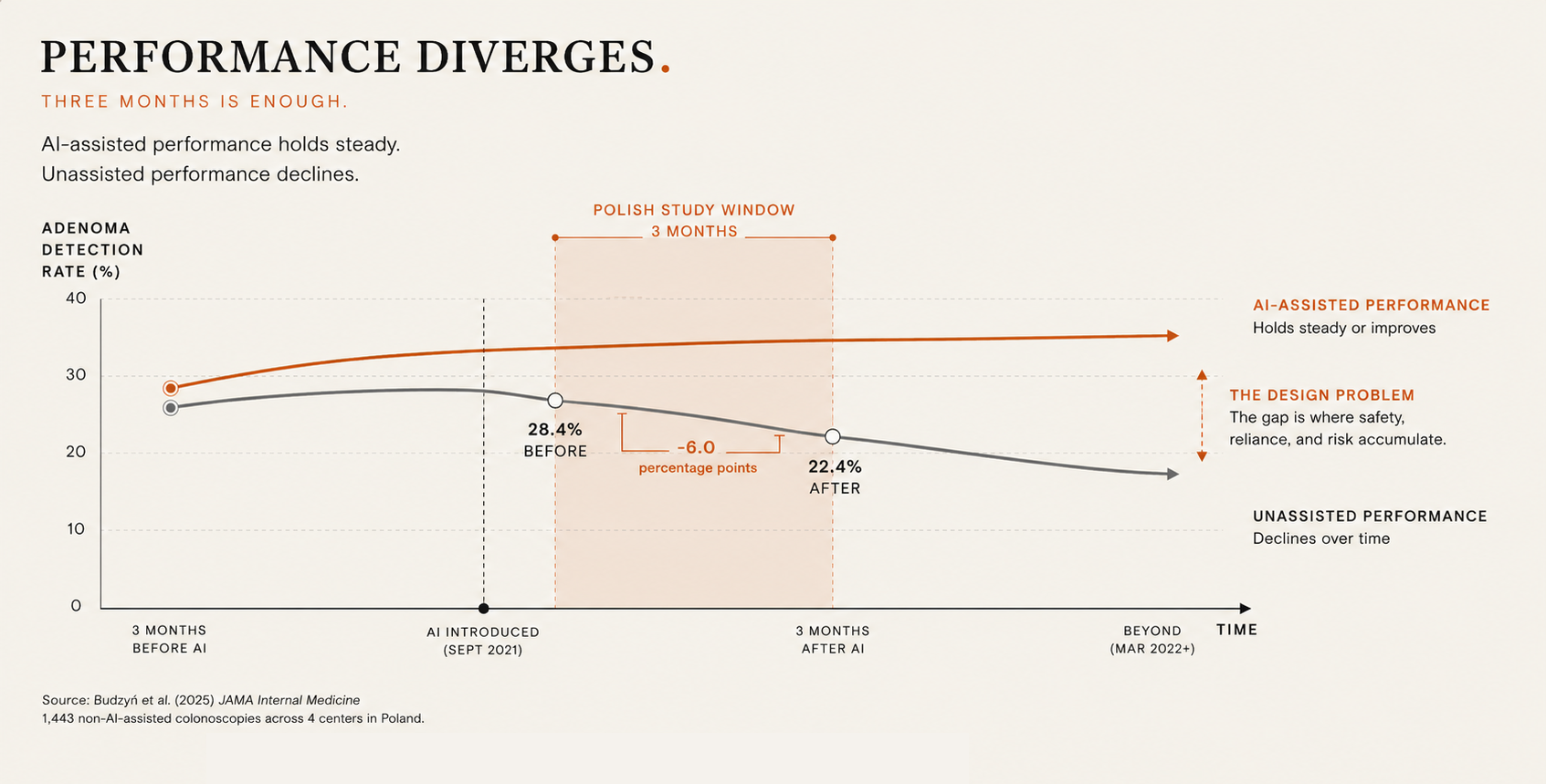
Three details make this finding worth an talking about. The decline took three months, not a career. It happened to 19 experienced endoscopists, not trainees. And nobody designed for it, because the deployment assumed the doctors' baseline skill would sit safely underneath the AI, unchanged, ready whenever the assistance was off.
The study is observational and the authors are careful about mechanism. It might be skill atrophy. It might be a behavioral shift, doctors learning to let the overlay do the looking. For a designer the distinction matters less than the fact that continuous exposure to the tool changed what the humans could do without it.
The 1983 warning
None of this would have surprised Lisanne Bainbridge. Her 1983 paper "Ironies of Automation," written about industrial process control, runs five pages of Automatica and describes the AI products of 2026 with uncomfortable precision.
The central irony runs like this. Designers automate whatever they can and leave the human to monitor that the automation is working, and to take over when it fails. Both jobs are precisely the ones automation makes people worse at. Skills deteriorate when they are not used, so the operator who has been watching a system run is less capable at the moment of takeover than the operator who was replaced. Vigilance research had already shown that humans cannot maintain effective attention on a source where almost nothing happens. And an operator cannot meaningfully check in real time the decisions of a machine that was installed because it decides better and faster than he or she does. Bainbridge called that last one an impossible task, and noted that "the most successful automated systems... may need the greatest investment in human operator training" (Bainbridge, 1983). By 1997 the field had a full taxonomy for how this plays out in practice, documenting overreliance, complacency, and automation bias across cockpits, control rooms, and intensive care units (Parasuraman & Riley, 1997).
Aviation spent the following decades confirming her. Casner, Geven, Recker, and Schooler (2014) put sixteen airline pilots in a Boeing 747-400 simulator and varied the level of automation. The hand-eye skills survived disuse. Instrument scanning and manual control stayed mostly intact even for pilots who rarely hand-flew. The decay showed up in the cognitive skills. Pilots who rarely hand-flew got worse at navigating without the flight computer, lost track of where the flight stood, and struggled to diagnose failures. Only one of sixteen pilots flew the manual navigation task without error. Task-unrelated thought nearly tripled under full automation, and the pilots who let their minds wander most made the most errors on the cognitive tasks.

Read those two results together and the pattern is specific. Automation does not erode skill uniformly. It erodes thinking skills first, and thinking is exactly what the human was retained to contribute.
Offloading or erosion
Humans have always offloaded cognition, and it has mostly been a good trade. Risko and Gilbert (2016) define cognitive offloading as using physical action to reduce the information processing a task demands, and the category includes writing, calculators, GPS, and every reminder you have ever set. Offloading lets people hold long-term goals, coordinate complex work, and achieve things unaided cognition cannot. Sparrow, Liu, and Wegner (2011) showed that when people expect information to remain available, they remember where to find it rather than what it says. That looks less like a deficit than a sensible division of labor with a machine.
The same literature contains the warning, though. Offloading decisions are driven by metacognitive judgments about our own abilities, and those judgments are often wrong. People in offloading studies write down items even when their memory for the task is already at ceiling, and access to search inflates confidence in unaided ability rather than deflating it (Risko & Gilbert, 2016). We offload more than we need to, and we are poor witnesses to what we are losing.
The GenAI-era evidence sharpens this into something measurable. Lee et al. (2025) surveyed 319 knowledge workers about 936 real tasks they had done with generative AI. The strongest predictor of whether someone thought critically about an output was their confidence in the AI, and the relationship was negative. Higher confidence in the tool meant less critical thinking. Higher confidence in one's own ability meant more critical thinking. Majorities reported spending less cognitive effort in every one of the six categories of thinking the study measured, and described their role shifting from doing the work to verifying and stewarding the AI's version of it. Simkute et al. (2025) traced the same shift through studies of AI-assisted programming and named the historical parallel directly. This is Bainbridge's production-to-monitoring move, replayed on knowledge work, with the added twist that automation makes easy tasks easier and hard tasks harder.
The most alarming result in circulation is also the weakest. Kosmyna et al. (2025) measured EEG connectivity in students writing essays with and without ChatGPT and found the weakest neural engagement in the LLM group, along with reduced memory for their own text. The paper is a preprint, it has drawn detailed methodological criticism (Stankovic et al., 2026), and its sample is small. It gets cited as proof that AI damages brains, which claims far more than the study can carry. On its own it is one unreviewed data point, consistent with the same, more boringly documented pattern.
Strip the rhetoric from both camps and the agreement is broad. Unused skills decay; nobody disputes this. Cognitive work is redistributed by these tools, not eliminated (Tankelevitch et al., 2024). Engagement moderates the loss; the pilots who kept their minds on task performed better, and the workers who trusted their own judgment thought harder. The real question is: does the new work, the verifying and stewarding, exercise the same expertise the old work built?
Deskilling is a design outcome
The public conversation treats deskilling as a user problem, a failure of discipline, as if the fix were telling people to think harder. Lab Notes 001 made the argument that trust calibration is a design problem wearing a user-problem costume. Deskilling is the same misdiagnosis repeated.
What decays is determined by what the interface asks you to practice. Every interface is a training regime, whether or not anyone designed it as one. A tool that always drafts first trains evaluation and only evaluation. One that presents every output with the same flat confidence trains acceptance, and one that fills every gap teaches the user to stop noticing gaps exist. The model determines none of this. The interaction design does, which means somebody chose it.

The designers who take this seriously have concrete options, and most of them are old. Bainbridge's remedies were design remedies. She wanted operators scheduled onto hands-on control, drilled in simulators for the rare failures, and given automation that fails visibly instead of gracefully. Her modern translations are recognizable. Let the human attempt the hard call before the AI shows its answer, the pattern the clinical literature would have wanted in the colonoscopy suite. Surface the model's confidence unevenly, so scrutiny is invited exactly where the system is weak, the calibration argument from Lab Notes 001 applied to skill instead of trust. And build unassisted reps into the workflow and instrument them, because the Polish study could only detect deskilling because randomization preserved an unassisted baseline. Most products have no such baseline. Their users' expertise could be draining and no one, including the users, would have the data to notice.
Tankelevitch et al. (2024) point at the deepest version of this. Generative AI shifts the burden of work onto metacognition. The user has to know what they want, judge whether the output is any good, and decide when to rely on it. A design can support those judgments or quietly make them for you. Practitioners can feel the difference. In Shukla et al.'s (2025) analysis of UX designers' own writing about AI tools, a recurring worry was losing exposure to the foundational thinking their judgment was built on.
The part the loop forgot
Lab Notes 002 ended with an architecture. The TT Auditor could handle roughly four fifths of a structured accessibility audit, and the remaining fifth required human expertise that were not optional. That division of labor is the honest version of human-in-the-loop, and it has a hidden dependency. It assumes the expert stays expert.
The deskilling evidence puts pressure on exactly that assumption. The judgment needed for the residual fifth was built through years of doing the whole audit, including the four fifths the tool now absorbs. The endoscopists in the Polish study were the safety layer for their AI, and three months of assisted work measurably changed what that layer could do alone. Human-in-the-loop assumes the human stays expert. The loop itself is what erodes the expertise it depends on.
None of this argues against the architecture, only that it carries a maintenance cost nobody is budgeting for. If a system consumes expert judgment as its backstop, it should be designed to keep that judgment exercised, the way aviation eventually accepted that automated cockpits require deliberate manual practice. Expertise, like trust, is a resource the system spends. It should be stewarded like one.
The honest conclusion
The evidence has real limits. The Lancet result is observational, from one country, over three months, and cannot separate skill loss from attention shift. Lee et al. measured self-reports, not performance, and say plainly that causation is not established. The EEG work is unreviewed. And no study has measured the thing this article most wants to know and that is whether sustained verification work builds a durable expertise of its own, or whether it is a skill that only functions on top of production experience it no longer renews.
What the evidence does support is a change in where responsibility sits. Deskilling is not a character flaw in users and not an inevitability of the technology. It is an outcome of interaction design decisions that are currently being made by default. A product team that knows what its interface trains, preserves an unassisted baseline, and spends design effort keeping its expert users as experts is maintaining the one component its safety story actually depends on: human expertise itself.
The tools are not going away, and they should not. The doctors detected more adenomas with the AI on. The point is what happens to everyone the day it is off.
References
Bainbridge, L. (1983). Ironies of automation. Automatica, 19(6), 775–779. https://doi.org/10.1016/0005-1098(83)90046-8
Budzyń, K., Romańczyk, M., Kitala, D., Kołodziej, P., Bugajski, M., Adami, H. O., et al. (2025). Endoscopist deskilling risk after exposure to artificial intelligence in colonoscopy: A multicentre, observational study. The Lancet Gastroenterology & Hepatology, 10(10), 896–903. https://doi.org/10.1016/S2468-1253(25)00133-5
Casner, S. M., Geven, R. W., Recker, M. P., & Schooler, J. W. (2014). The retention of manual flying skills in the automated cockpit. Human Factors, 56(8), 1506–1516. https://doi.org/10.1177/0018720814535628
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X.-H., Beresnitzky, A. V., Braunstein, I., & Maes, P. (2025). Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task (arXiv:2506.08872). arXiv. https://doi.org/10.48550/arXiv.2506.08872
Lee, H.-P. (H.), Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N. (2025). The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. ACM. https://doi.org/10.1145/3706598.3713778
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2), 230–253. https://doi.org/10.1518/001872097778543886
Risko, E. F., & Gilbert, S. J. (2016). Cognitive offloading. Trends in Cognitive Sciences, 20(9), 676–688. https://doi.org/10.1016/j.tics.2016.07.002
Shukla, P., Bui, P., Levy, S., Kowalski, M., Baigelenov, A., & Parsons, P. (2025). De-skilling, cognitive offloading, and misplaced responsibilities: Potential ironies of AI-assisted design. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA '25). ACM. https://doi.org/10.1145/3706599.3719931
Simkute, A., Tankelevitch, L., Kewenig, V., Scott, A. E., Sellen, A., & Rintel, S. (2025). Ironies of generative AI: Understanding and mitigating productivity loss in human-AI interaction. International Journal of Human–Computer Interaction, 41(5), 2898–2919. https://doi.org/10.1080/10447318.2024.2405782
Sparrow, B., Liu, J., & Wegner, D. M. (2011). Google effects on memory: Cognitive consequences of having information at our fingertips. Science, 333(6043), 776–778. https://doi.org/10.1126/science.1207745
Stankovic, M., Hirche, E., Kollatzsch, S., & Doetsch, J. N. (2026). Comment on: Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing tasks (arXiv:2601.00856). arXiv. https://arxiv.org/abs/2601.00856
Tankelevitch, L., Kewenig, V., Simkute, A., Scott, A. E., Sarkar, A., Sellen, A., & Rintel, S. (2024). The metacognitive demands and opportunities of generative AI. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. ACM. https://doi.org/10.1145/3613904.3642902